Vision Transformer from Scratch¶
Overview of ViT:¶
ViT's architecture was inspired by BERT, an encoder-only transformer model that is often used in NLP supervised learning tasks like text classfication or named entity recognition. The main idea behind ViT is that an image can be seen as series of patches, which can be treated as tokens in NLP tasks.
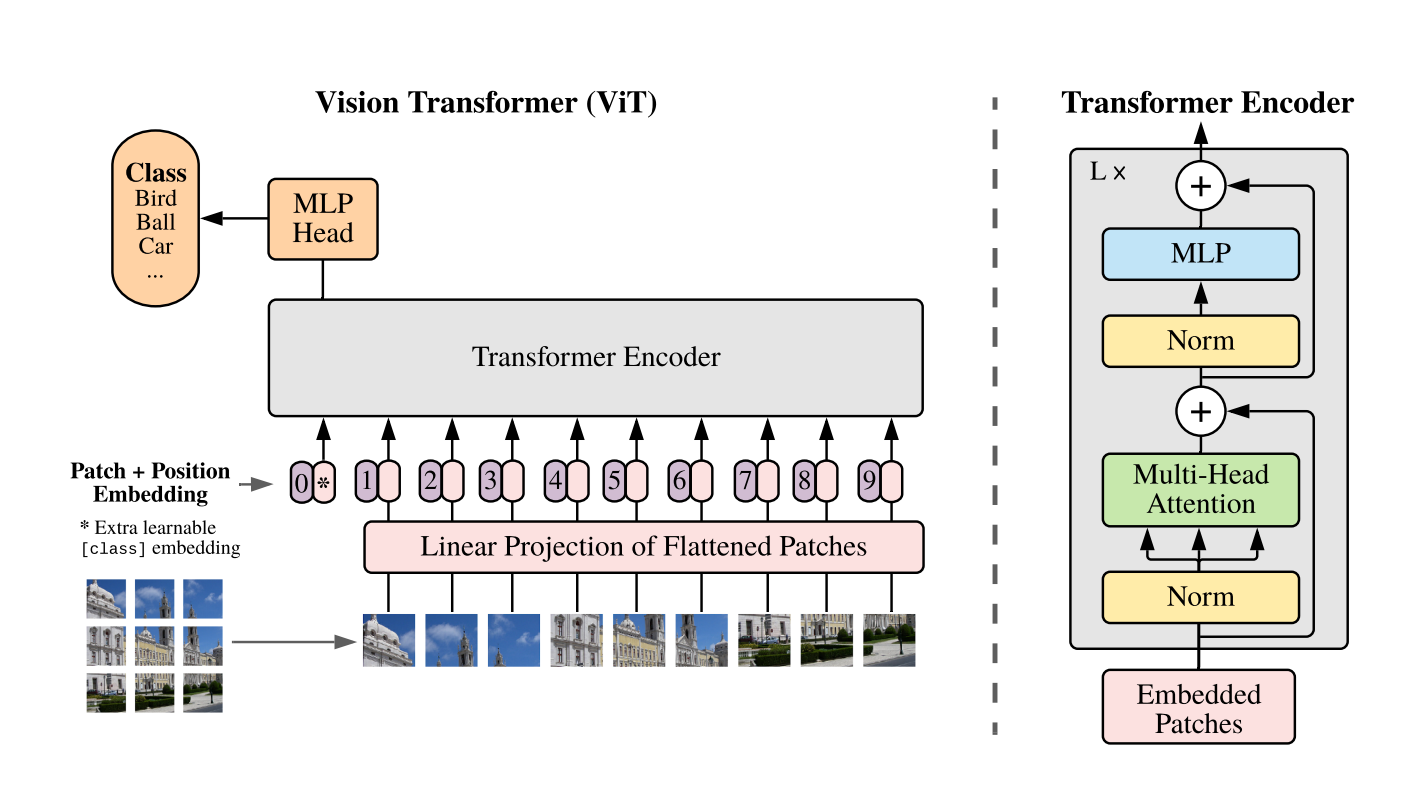
The input image is split into small patches, which are then flattened to sequences of vectors. These vectors are then processed by a transformer encoder, which allows the model to learn the interactions between patches through self-attention mechanism. The output of the transformer encoder is then fed into a classfication layer that outputs the predicted class of the input image.
import json
import os
import math
import numpy as np
import matplotlib.pyplot as plt
import torch
import torchvision
Transform Images into Embeddings¶
In order to feed input images to a Transformer model, we need to convert the images into a sequence of vectors. This is done by splitting the image into a grid of non-overlapping patches, which are then linearly projected to obtain a fixed-size embedding vector for each patch.
class PatchEmbeddings(torch.nn.Module):
'''
Convert the image into patches and then project them into a vector space.
'''
def __init__(self, config):
super().__init__()
self.image_size = config['image_size']
self.patch_size = config['patch_size']
self.num_channels = config['num_channels']
self.hidden_size = config['hidden_size']
# Calculate the number of patches from the image size and patch size
self.num_patches = (self.image_size // self.patch_size) ** 2
# Create a projection layer to convert the image into patches
# The layer projects each patch into a vector of size hidden_size
self.projection = torch.nn.Conv2d(
self.num_channels, self.hidden_size,
kernel_size=self.patch_size, stride=self.patch_size
)
def forward(self, x):
# (batch_size, num_channels, image_size, image_size) -> (batch_size, num_patches, hidden_size)
x = self.projection(x)
x = x.flatten(2).transpose(1, 2)
return x
After the patches are converted to a sequence of embeddings, the [CLS] token is added to the beginning of the sequence, it will be used later in the classification layer to classify the image. The [CLS] token's embedding is learned during training.
As patches from different positions may contribute differently to the final predictions, we also need to encode patch positions into the sequence. We are going to use learnable position embeddings to add positional imformation and embeddings.
class Embeddings(torch.nn.Module):
'''
Combine the patch embeddings with the class token and position embeddings.
'''
def __init__(self, config):
super().__init__()
self.config = config
self.patch_embeddings = PatchEmbeddings(config)
# Create learnable [CLS] token
# Similar to BERT, the [CLS] token is added to the beginning of the input sequence
# and is used to classify the entire sequence
self.cls_token = torch.nn.Parameter(torch.rand(1, 1, config['hidden_size']))
# Create the positional encoding of [CLS] token and the patch embeddings
# Add 1 to the sequence length for the [CLS] token
self.positional_embeddings = \
torch.nn.Parameter(torch.randn(1, self.patch_embeddings.num_patches+1, config['hidden_size']))
self.dropout = torch.nn.Dropout(config['hidden_dropout_prob'])
def forward(self, x):
x = self.patch_embeddings(x)
batch_size, _, _ = x.size()
# Expand the [CLS] token to the batch size
# (1, 1, hidden_size) -> (batch_size, 1, hidden_size)
cls_tokens = self.cls_token.expand(batch_size, -1, -1)
# Concatenate the [CLS] token to the beginning of the input sequence
# This results in a sequence length of (num_patches+1)
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.positional_embeddings
x = self.dropout(x)
return x
At this step, the input image is converted to a sequence of embeddings with positional information and ready to be fed into the transformer layer .
Multi-Head Attention¶
The multi-head attention is used to compute the interactions between different patches in the input image. The multi-head attention consists of multiple attention heads, each of which is a single attention layer.
The module takes a sequence of embeddings as input and computes query, key, and value vectors for each embedding. The query and key vectors are then used to compute the attention weights for each token. The attention weights are then used to compute new embeddings using a weighted sum of the value vectors.
class AttentionHead(torch.nn.Module):
'''
A single attention head.
This module is used in the `MultiHeadAttention` module
'''
def __init__(self, hidden_size, attention_head_size, dropout, bias=True):
super().__init__()
self.hidden_size = hidden_size
self.attention_head_size = attention_head_size
# Create the query, key, and value projection layers
self.query = torch.nn.Linear(hidden_size, attention_head_size, bias=bias)
self.key = torch.nn.Linear(hidden_size, attention_head_size, bias=bias)
self.value = torch.nn.Linear(hidden_size, attention_head_size, bias=bias)
self.dropout = torch.nn.Dropout(dropout)
def forward(self, x):
# Project the input into query, key, and value
# The same input is used to generate the query, key, and value,
# and hence, it's usually called self-attention
# (batch_size, sequence_length, hidden_size) -> (batch_size, sequence_length, attention_head_size)
query = self.query(x)
key = self.key(x)
value = self.value(x)
# Calculate the attention score: softmax(Q * K.T / sqrt(head_size)) * V
attention_scores = torch.matmul(query, key.transpose(-1, -2))
attention_scores /= math.sqrt(self.attention_head_size)
attention_probs = torch.nn.functional.softmax(attention_scores, dim=-1)
attention_probs = self.dropout(attention_probs)
attention_output = torch.matmul(attention_probs, value)
return (attention_output, attention_probs)
The outputs from all the attention heads are then concatenated and linearly projected to obtain the final output of the multi-head attention module.
class MultiHeadAttention(torch.nn.Module):
'''
Multi-head Attention Module.
This module will be used in the TransformerEncoder module.
'''
def __init__(self, config):
super().__init__()
self.hidden_size = config['hidden_size']
self.num_attention_heads = config['num_attention_heads']
self.attention_head_size = self.hidden_size // self.num_attention_heads
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.qkv_bias = config['qkv_bias']
# Create a list of attention heads
self.heads = torch.nn.ModuleList([
AttentionHead(
self.hidden_size, self.attention_head_size,
config['attention_probs_dropout_prob'], self.qkv_bias)
for _ in range(self.num_attention_heads)
])
# Create a linear layer to project the attention output back to the hidden size
# In most cases, all_head_size and hidden_size are the same
self.output_projection = torch.nn.Linear(self.all_head_size, self.hidden_size)
self.output_dropout = torch.nn.Dropout(config['hidden_dropout_prob'])
def forward(self, x, output_attentions=False):
# Calculate the attention output for each attention head
attention_outputs = [head(x) for head in self.heads]
# Concatenate the attention outputs from each attention head
attention_output = torch.cat([attention_output for attention_output, _ in attention_outputs], dim=-1)
# Project the attention output back to the hidden size
attention_output = self.output_projection(attention_output)
attention_output = self.output_dropout(attention_output)
# Return the attention output and the attention probabilities
if not output_attentions:
return (attention_output, None)
attention_probs = torch.stack([attention_probs for _, attention_probs in attention_outputs], dim=1)
return (attention_output, attention_probs)
Transformer Encoder¶
The transformer encoder is made of a stack of transformer layers. Each transformer layer mainly consists of a multi-head attention module and a feed-forward network. To better scale the model and stabilize training two Layer Normalization layers and skip connections are added to the transformer layer.
class GELUActivation(torch.nn.Module):
'''
Implementation of the GELU Activation function currently in Google BERT repository,
Taken from https://github.com/huggingface/transformers/blob/main/src/transformers/activations.py
'''
def forward(self, x):
return 0.5 * x * (1.0 + torch.tanh(math.sqrt(2.0 / math.pi) * (x + 0.044715 * torch.pow(x, 3.0))))
class MLP(torch.nn.Module):
'''
A multi-layer perceptron module.
'''
def __init__(self, config):
super().__init__()
self.dense_1 = torch.nn.Linear(config['hidden_size'], config['intermediate_size'])
self.activation = GELUActivation()
self.dense_2 = torch.nn.Linear(config['intermediate_size'], config['hidden_size'])
self.dropout = torch.nn.Dropout(config['hidden_dropout_prob'])
def forward(self, x):
x = self.dense_1(x)
x = self.activation(x)
x = self.dense_2(x)
x = self.dropout(x)
return x
class Block(torch.nn.Module):
'''
A single transformer block
'''
def __init__(self, config):
super().__init__()
self.attention = MultiHeadAttention(config)
self.layernorm_1 = torch.nn.LayerNorm(config['hidden_size'])
self.mlp = MLP(config)
self.layernorm_2 = torch.nn.LayerNorm(config['hidden_size'])
def forward(self, x, output_attentions=False):
# self-attention
attention_output, attention_probs = \
self.attention(self.layernorm_1(x), output_attentions=output_attentions)
# skip-connections
x = x + attention_output
# feed-forward network
mlp_output = self.mlp(self.layernorm_2(x))
# skip-connections
x = x + mlp_output
# Return the transformer block's output and the attention probabilities (optional)
if not output_attentions:
return (x, None)
return (x, attention_probs)
class Encoder(torch.nn.Module):
'''
The transformer encoder module.
'''
def __init__(self, config):
super().__init__()
# Create a list of transformer blocks
self.blocks = torch.nn.ModuleList([
Block(config) for _ in range(config['num_hidden_layers'])
])
def forward(self, x, output_attentions=False):
# Calculate the transformer block's output for each block
all_attentions = []
for block in self.blocks:
x, attention_probs = block(x, output_attentions=output_attentions)
if output_attentions:
all_attentions.append(attention_probs)
# Return the encoder's output and the attention probabilities (optional)
if not output_attentions:
return (x, None)
return (x, all_attentions)
ViT For Image Classification¶
After inputting the image to the embedding layer and transformer encoder, we obtain new encodings for both the image patches and the [CLS] token. At this point, the embeddings should have some useful signals for classification after being processed by the transformer encoder. Similar to BERT, we will use only the [CLS] token's embedding to pass to the classification layer.
The classification layer is a fully connected layer that takes the [CLS] embedding as input and outputs logits for each image.
class ViT4Classification(torch.nn.Module):
'''
The ViT Model for Classification
'''
def __init__(self, config):
super().__init__()
self.config = config
self.image_size = config['image_size']
self.hidden_size = config['hidden_size']
self.num_classes = config['num_classes']
# Create the embedding module
self.embedding = Embeddings(config)
# Create the transformer encoder module
self.encoder = Encoder(config)
# Create a linear layer to project the encoder's output to the number of classes
self.classifier = torch.nn.Linear(self.hidden_size, self.num_classes)
def forward(self, x, output_attentions=False):
# Calculate the embedding output
embedding_output = self.embedding(x)
# Calculate the encoder's output
encoder_output, all_attentions = self.encoder(embedding_output, output_attentions=output_attentions)
# Calculate the logits, take the [CLS] token's output as features for classification
logits = self.classifier(encoder_output[:, 0])
# Return the logits and the attention probabilities (optional)
if not output_attentions:
return (logits, None)
return (logits, all_attentions)
Utility methods¶
def save_experiments(experiment_name, config, model, train_losses, test_losses, accuracies, base_dir='experiments'):
outdir = os.path.join(base_dir, experiment_name)
os.makedirs(outdir, exist_ok=True)
# Save the config
configfile = os.path.join(outdir, 'config.json')
with open(configfile, 'w') as f:
json.dump(config, f, sort_keys=True, indent=4)
# Save the metric
jsonfile = os.path.join(outdir, 'metrics.json')
with open(jsonfile, 'w') as f:
data = {
'train_losses': train_losses,
'test_losses': test_losses,
'accuracies': accuracies
}
json.dump(data, f, sort_keys=True, indent=4)
save_checkpoint(experiment_name, model, 'final', base_dir=base_dir)
def save_checkpoint(experiment_name, model, epoch, base_dir='experiments'):
outdir = os.path.join(base_dir, experiment_name)
os.makedirs(outdir, exist_ok=True)
cpfile = os.path.join(outdir, f'model_{epoch}.pt')
torch.save(model.state_dict(), cpfile)
def load_experiment(experiment_name, checkpoint_name='model_final.pt', base_dir='experiments'):
outdir = os.path.join(base_dir, experiment_name)
# Load the config
configfile = os.path.join(outdir, 'config.json')
with open(configfile, 'r') as f:
config = json.load(f)
# Load the metrics
jsonfile = os.path.join(outdir, 'metrics.json')
with open(jsonfile, 'r') as f:
data = json.load(f)
train_losses = data['train_losses']
test_losses = data['test_losses']
accuracies = data['accuracies']
# Load the model
model = ViT4Classification(config)
cpfile = os.path.join(outdir, checkpoint_name)
model.load_state_dict(torch.load(cpfile))
return config, model, train_losses, test_losses, accuracies
def visualize_images():
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
indices = torch.randperm(len(trainset))[:30]
images = [np.asarray(trainset[i][0]) for i in indices]
labels = [trainset[i][1] for i in indices]
fig = plt.figure(figsize=(10, 10))
for i in range(30):
ax = fig.add_subplot(6, 5, i+1, xticks=[], yticks=[])
ax.imshow(images[i])
ax.set_title(classes[labels[i]])
@torch.no_grad()
def visualize_attention(model, output=None, device='cuda'):
model.eval()
num_images = 30
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
indices = torch.randperm(len(testset))[:num_images]
raw_images = [np.asarray(testset[i][0]) for i in indices]
labels = [testset[i][1] for i in indices]
test_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Resize((32, 32)),
torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
images = torch.stack([test_transform(image) for image in raw_images])
images = images.to(device)
model = model.to(device)
# Get attention maps from the last block
logits, attention_maps = model(images, output_attentions=True)
predictions = torch.argmax(logits, dim=1)
# Concatenate the attention maps from all blocks
attention_maps = torch.cat(attention_maps, dim=1)
# select only the attention maps of the [CLS] token
attention_maps = attention_maps[:, :, 0, 1:]
# average the attention maps of the [CLS] token over all the heads
attention_maps = attention_maps.mean(dim=1)
# Reshape the attention maps to a square
num_patches = attention_maps.size(-1)
size = int(math.sqrt(num_patches))
attention_maps = attention_maps.view(-1, size, size)
# Resize the map to the size of the image
attention_maps = attention_maps.unsqueeze(1)
attention_maps = torch.nn.functional.interpolate(attention_maps, size=(32, 32), mode='bilinear', align_corners=False)
attention_maps = attention_maps.squeeze(1)
fig = plt.figure(figsize=(20, 10))
mask = np.concatenate([np.ones((32, 32)), np.zeros((32, 32))], axis=1)
for i in range(num_images):
ax = fig.add_subplot(6, 5, i+1, xticks=[], yticks=[])
img = np.concatenate([raw_images[i], raw_images[i]], axis=1)
ax.imshow(img)
extended_attention_map = np.concatenate((np.zeros((32, 32)), attention_maps[i].cpu()), axis=1)
extended_attention_map = np.ma.masked_where(mask==1, extended_attention_map)
ax.imshow(extended_attention_map, alpha=0.5, cmap='jet')
gt = classes[labels[i]]
pred = classes[predictions[i]]
ax.set_title(f'gt: {gt} / pred: {pred}', color=('green' if gt==pred else 'red'))
if output is None:
plt.savefig(output)
plt.show()
Dataset preparation¶
def prepare_data(batch_size=4, num_workers=4, train_sample_size=None, test_sample_size=None):
train_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Resize((32, 32)),
torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=train_transform)
if train_sample_size is not None:
indices = torch.randperm(len(trainset))[:train_sample_size]
trainset = torch.utils.data.Subset(trainset, indices)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batch_size, num_workers=num_workers, shuffle=True)
test_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Resize((32, 32)),
torchvision.transforms.RandomHorizontalFlip(p=0.5),
torchvision.transforms.RandomResizedCrop((32, 32), scale=(0.8, 1.0), ratio=(0.75, 1.3333)),
torchvision.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=train_transform)
if test_sample_size is not None:
indices = torch.randperm(len(testset))[:test_sample_size]
testset = torch.utils.data.Subset(testset, indices)
testloader = torch.utils.data.DataLoader(testset, batch_size=batch_size, num_workers=num_workers, shuffle=False)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
return trainloader, testloader, classes
Training¶
config = {
'patch_size': 4,
'hidden_size': 48,
'num_hidden_layers': 4,
'num_attention_heads': 4,
'intermediate_size': 4 * 48,
'hidden_dropout_prob': 0.0,
'attention_probs_dropout_prob': 0.0,
'initializer_range': 0.02,
'image_size': 32,
'num_classes': 10,
'num_channels': 3,
'qkv_bias': True,
}
assert config['hidden_size'] % config['num_attention_heads'] == 0
assert config['intermediate_size'] == 4 * config['hidden_size']
assert config['image_size'] % config['patch_size'] == 0
class Trainer:
def __init__(self, model, optimizer, loss_fn, exp_name, device):
self.model = model.to(device)
self.optimizer = optimizer
self.loss_fn = loss_fn
self.exp_name = exp_name
self.device = device
def train(self, trainloader, testloader, epochs, save_model_every_n_epochs=0):
train_losses, test_losses, accuracies = [], [], []
for i in range(epochs):
train_loss = self.train_epoch(trainloader)
accuracy, test_loss = self.evaluate(testloader)
train_losses.append(train_loss)
test_losses.append(test_loss)
accuracies.append(accuracy)
print(f'Epoch: {i+1}, Train loss: {train_loss:.4f}, Test loss: {test_loss:.4f}, Accuracy: {accuracy:.4f}')
if save_model_every_n_epochs > 0 and (i+1) % save_model_every_n_epochs == 0 and i+1 != epochs:
print('\tSave checkpoint at epoch', i+1)
save_checkpoint(self.exp_name, self.model, i+1)
save_experiments(self.exp_name, config, self.model, train_losses, test_losses, accuracies)
def train_epoch(self, trainloader):
self.model.train()
total_loss = 0.0
for batch in trainloader:
batch = [t.to(self.device) for t in batch]
images, labels = batch
self.optimizer.zero_grad()
loss = self.loss_fn(self.model(images)[0], labels)
loss.backward()
self.optimizer.step()
total_loss += loss.item() * len(images)
return total_loss / len(trainloader.dataset)
@torch.no_grad()
def evaluate(self, testloader):
self.model.eval()
total_loss = 0.0
correct = 0
with torch.no_grad():
for batch in testloader:
batch = [t.to(self.device) for t in batch]
images, labels = batch
logits, _ = self.model(images)
predictions = torch.argmax(logits, dim=1)
loss = self.loss_fn(logits, labels)
total_loss += loss.item() * len(images)
correct += torch.sum(predictions==labels).item()
accuracy = correct / len(testloader.dataset)
avg_loss = total_loss / len(testloader.dataset)
return accuracy, avg_loss
Main¶
trainloader, testloader, classes = prepare_data(batch_size=128)
model = ViT4Classification(config)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-2)
loss_fn = torch.nn.CrossEntropyLoss()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print(device)
trainer = Trainer(model, optimizer, loss_fn, 'experiment_1', device)
trainer.train(trainloader, testloader, 100, 10)
Files already downloaded and verified Files already downloaded and verified cuda:0 Epoch: 1, Train loss: 1.7262, Test loss: 1.5091, Accuracy: 0.4470 Epoch: 2, Train loss: 1.4486, Test loss: 1.3294, Accuracy: 0.5186 Epoch: 3, Train loss: 1.3378, Test loss: 1.2889, Accuracy: 0.5316 Epoch: 4, Train loss: 1.2562, Test loss: 1.2524, Accuracy: 0.5457 Epoch: 5, Train loss: 1.1954, Test loss: 1.1975, Accuracy: 0.5777 Epoch: 6, Train loss: 1.1502, Test loss: 1.1899, Accuracy: 0.5693 Epoch: 7, Train loss: 1.1035, Test loss: 1.1221, Accuracy: 0.5930 Epoch: 8, Train loss: 1.0564, Test loss: 1.1375, Accuracy: 0.5870 Epoch: 9, Train loss: 1.0332, Test loss: 1.0784, Accuracy: 0.6127 Epoch: 10, Train loss: 0.9958, Test loss: 1.0771, Accuracy: 0.6188 Save checkpoint at epoch 10 Epoch: 11, Train loss: 0.9721, Test loss: 1.0523, Accuracy: 0.6245 Epoch: 12, Train loss: 0.9484, Test loss: 1.0536, Accuracy: 0.6192 Epoch: 13, Train loss: 0.9254, Test loss: 1.1227, Accuracy: 0.6052 Epoch: 14, Train loss: 0.9107, Test loss: 1.0240, Accuracy: 0.6279 Epoch: 15, Train loss: 0.8858, Test loss: 1.0418, Accuracy: 0.6274 Epoch: 16, Train loss: 0.8685, Test loss: 1.0770, Accuracy: 0.6131 Epoch: 17, Train loss: 0.8554, Test loss: 1.0453, Accuracy: 0.6335 Epoch: 18, Train loss: 0.8393, Test loss: 1.0373, Accuracy: 0.6410 Epoch: 19, Train loss: 0.8273, Test loss: 1.0217, Accuracy: 0.6434 Epoch: 20, Train loss: 0.8095, Test loss: 1.0549, Accuracy: 0.6375 Save checkpoint at epoch 20 Epoch: 21, Train loss: 0.7972, Test loss: 1.1409, Accuracy: 0.6254 Epoch: 22, Train loss: 0.7768, Test loss: 1.0657, Accuracy: 0.6382 Epoch: 23, Train loss: 0.7643, Test loss: 1.0319, Accuracy: 0.6457 Epoch: 24, Train loss: 0.7513, Test loss: 1.0420, Accuracy: 0.6528 Epoch: 25, Train loss: 0.7380, Test loss: 1.0642, Accuracy: 0.6413 Epoch: 26, Train loss: 0.7234, Test loss: 1.0910, Accuracy: 0.6311 Epoch: 27, Train loss: 0.7193, Test loss: 1.0465, Accuracy: 0.6440 Epoch: 28, Train loss: 0.7008, Test loss: 1.1100, Accuracy: 0.6345 Epoch: 29, Train loss: 0.6936, Test loss: 1.0742, Accuracy: 0.6483 Epoch: 30, Train loss: 0.6869, Test loss: 1.0715, Accuracy: 0.6371 Save checkpoint at epoch 30 Epoch: 31, Train loss: 0.6737, Test loss: 1.0966, Accuracy: 0.6505 Epoch: 32, Train loss: 0.6664, Test loss: 1.0794, Accuracy: 0.6481 Epoch: 33, Train loss: 0.6455, Test loss: 1.1018, Accuracy: 0.6485 Epoch: 34, Train loss: 0.6408, Test loss: 1.0734, Accuracy: 0.6513 Epoch: 35, Train loss: 0.6355, Test loss: 1.1319, Accuracy: 0.6467 Epoch: 36, Train loss: 0.6285, Test loss: 1.1152, Accuracy: 0.6479 Epoch: 37, Train loss: 0.6187, Test loss: 1.1122, Accuracy: 0.6381 Epoch: 38, Train loss: 0.6242, Test loss: 1.0804, Accuracy: 0.6534 Epoch: 39, Train loss: 0.6009, Test loss: 1.0403, Accuracy: 0.6580 Epoch: 40, Train loss: 0.5883, Test loss: 1.1410, Accuracy: 0.6470 Save checkpoint at epoch 40 Epoch: 41, Train loss: 0.5903, Test loss: 1.1253, Accuracy: 0.6481 Epoch: 42, Train loss: 0.5857, Test loss: 1.1449, Accuracy: 0.6460 Epoch: 43, Train loss: 0.5770, Test loss: 1.0539, Accuracy: 0.6572 Epoch: 44, Train loss: 0.5620, Test loss: 1.1547, Accuracy: 0.6478 Epoch: 45, Train loss: 0.5671, Test loss: 1.1310, Accuracy: 0.6470 Epoch: 46, Train loss: 0.5553, Test loss: 1.1024, Accuracy: 0.6530 Epoch: 47, Train loss: 0.5522, Test loss: 1.2653, Accuracy: 0.6339 Epoch: 48, Train loss: 0.5405, Test loss: 1.1992, Accuracy: 0.6440 Epoch: 49, Train loss: 0.5429, Test loss: 1.1400, Accuracy: 0.6521 Epoch: 50, Train loss: 0.5334, Test loss: 1.1589, Accuracy: 0.6555 Save checkpoint at epoch 50 Epoch: 51, Train loss: 0.5361, Test loss: 1.2131, Accuracy: 0.6399 Epoch: 52, Train loss: 0.5176, Test loss: 1.1613, Accuracy: 0.6531 Epoch: 53, Train loss: 0.5165, Test loss: 1.1720, Accuracy: 0.6572 Epoch: 54, Train loss: 0.5075, Test loss: 1.2345, Accuracy: 0.6532 Epoch: 55, Train loss: 0.5114, Test loss: 1.2345, Accuracy: 0.6442 Epoch: 56, Train loss: 0.5023, Test loss: 1.1732, Accuracy: 0.6544 Epoch: 57, Train loss: 0.4956, Test loss: 1.2258, Accuracy: 0.6542 Epoch: 58, Train loss: 0.4897, Test loss: 1.2470, Accuracy: 0.6477 Epoch: 59, Train loss: 0.5022, Test loss: 1.2088, Accuracy: 0.6550 Epoch: 60, Train loss: 0.4855, Test loss: 1.3200, Accuracy: 0.6433 Save checkpoint at epoch 60 Epoch: 61, Train loss: 0.4767, Test loss: 1.2518, Accuracy: 0.6477 Epoch: 62, Train loss: 0.4833, Test loss: 1.2604, Accuracy: 0.6523 Epoch: 63, Train loss: 0.4718, Test loss: 1.2473, Accuracy: 0.6485 Epoch: 64, Train loss: 0.4709, Test loss: 1.3252, Accuracy: 0.6439 Epoch: 65, Train loss: 0.4803, Test loss: 1.2526, Accuracy: 0.6466 Epoch: 66, Train loss: 0.4625, Test loss: 1.2875, Accuracy: 0.6478 Epoch: 67, Train loss: 0.4685, Test loss: 1.3390, Accuracy: 0.6359 Epoch: 68, Train loss: 0.4627, Test loss: 1.4036, Accuracy: 0.6353 Epoch: 69, Train loss: 0.4601, Test loss: 1.2649, Accuracy: 0.6578 Epoch: 70, Train loss: 0.4525, Test loss: 1.3097, Accuracy: 0.6482 Save checkpoint at epoch 70 Epoch: 71, Train loss: 0.4531, Test loss: 1.3916, Accuracy: 0.6489 Epoch: 72, Train loss: 0.4409, Test loss: 1.2333, Accuracy: 0.6515 Epoch: 73, Train loss: 0.4341, Test loss: 1.3603, Accuracy: 0.6431 Epoch: 74, Train loss: 0.4483, Test loss: 1.2759, Accuracy: 0.6564 Epoch: 75, Train loss: 0.4410, Test loss: 1.3998, Accuracy: 0.6357 Epoch: 76, Train loss: 0.4359, Test loss: 1.3848, Accuracy: 0.6412 Epoch: 77, Train loss: 0.4387, Test loss: 1.2860, Accuracy: 0.6439 Epoch: 78, Train loss: 0.4186, Test loss: 1.2968, Accuracy: 0.6502 Epoch: 79, Train loss: 0.4360, Test loss: 1.3130, Accuracy: 0.6533 Epoch: 80, Train loss: 0.4127, Test loss: 1.4181, Accuracy: 0.6438 Save checkpoint at epoch 80 Epoch: 81, Train loss: 0.4277, Test loss: 1.3650, Accuracy: 0.6474 Epoch: 82, Train loss: 0.4194, Test loss: 1.4545, Accuracy: 0.6467 Epoch: 83, Train loss: 0.4160, Test loss: 1.3058, Accuracy: 0.6568 Epoch: 84, Train loss: 0.4105, Test loss: 1.3121, Accuracy: 0.6435 Epoch: 85, Train loss: 0.4112, Test loss: 1.3770, Accuracy: 0.6405 Epoch: 86, Train loss: 0.4148, Test loss: 1.3921, Accuracy: 0.6449 Epoch: 87, Train loss: 0.4167, Test loss: 1.4562, Accuracy: 0.6359 Epoch: 88, Train loss: 0.4005, Test loss: 1.4552, Accuracy: 0.6455 Epoch: 89, Train loss: 0.4141, Test loss: 1.3922, Accuracy: 0.6416 Epoch: 90, Train loss: 0.3985, Test loss: 1.3749, Accuracy: 0.6367 Save checkpoint at epoch 90 Epoch: 91, Train loss: 0.4007, Test loss: 1.3759, Accuracy: 0.6464 Epoch: 92, Train loss: 0.3981, Test loss: 1.4146, Accuracy: 0.6544 Epoch: 93, Train loss: 0.3963, Test loss: 1.4741, Accuracy: 0.6396 Epoch: 94, Train loss: 0.3876, Test loss: 1.5125, Accuracy: 0.6364 Epoch: 95, Train loss: 0.4038, Test loss: 1.5152, Accuracy: 0.6288 Epoch: 96, Train loss: 0.3862, Test loss: 1.5016, Accuracy: 0.6412 Epoch: 97, Train loss: 0.3995, Test loss: 1.5222, Accuracy: 0.6479 Epoch: 98, Train loss: 0.3872, Test loss: 1.5301, Accuracy: 0.6424 Epoch: 99, Train loss: 0.3828, Test loss: 1.6445, Accuracy: 0.6298 Epoch: 100, Train loss: 0.3930, Test loss: 1.3864, Accuracy: 0.6556
visualize_images()
Files already downloaded and verified

config, model, train_losses, test_losses, accuracies = load_experiment('experiment_1')
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 5))
ax1.plot(train_losses, label='Train loss')
ax1.plot(test_losses, label='Test loss')
ax1.set_xlabel('Epoch')
ax1.set_ylabel('Loss')
ax1.legend()
ax2.plot(accuracies)
ax2.set_xlabel('Epoch')
ax2.set_ylabel('Accuracy')
plt.savefig('metrics.png')
plt.show()

visualize_attention(model, 'attention.png')
Files already downloaded and verified
/opt/conda/lib/python3.10/site-packages/torchvision/transforms/functional.py:152: UserWarning: The given NumPy array is not writable, and PyTorch does not support non-writable tensors. This means writing to this tensor will result in undefined behavior. You may want to copy the array to protect its data or make it writable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /usr/local/src/pytorch/torch/csrc/utils/tensor_numpy.cpp:206.) img = torch.from_numpy(pic.transpose((2, 0, 1))).contiguous()
